

GANet: multi-modal adaptation continuous sign language recognition via gloss-aware network
 0
0 Abstract
Continuous sign language recognition (CSLR) aims to model the temporal evolution of visual gestures to recognize continuous semantic units, which is of great significance for applications in deaf communication assistance and intelligent human–computer interaction. While existing methods emphasize local segment modeling and long-range dependency capture, they often overlook the critical role of global semantic context in overall video comprehension—an oversight that contradicts the inherently context-dependent nature of sign language. Moreover, sign language videos frequently contain a large number of visually similar but semantically meaningless motions. These misleading segments are easily misperceived as valid glosses, thereby degrading recognition accuracy. To address these challenges, we propose GANet (Gloss-Aware Network), a novel CSLR framework with cross-modal input adaptability. Inspired by the hierarchical structure of "book–chapter–content", GANet explicitly models global context to guide local understanding while effectively suppressing irrelevant motion noise. Specifically, we introduce a Global Context Modeling Module to capture semantic patterns across frames and an auxiliary task to enhance the model's ability to learn high-level structural semantics. In addition, we propose a Gloss-Aware Module that leverages global semantics to model the spatiotemporal occurrence of glosses, thereby improving the recognition of meaningful gestures. Extensive experiments on multiple benchmark datasets demonstrate that GANet outperforms existing methods, validating its effectiveness, robustness, and broad adaptability to both RGB (red, green, and blue) and event-based data.
Keywords
INTRODUCTION
Sign language serves as the primary means of communication for the deaf community, where meaning is conveyed through continuous hand movements and context-dependent semantic cues. However, video-based sign language recognition inherently involves complex motion patterns that contain a large proportion of redundant or non-semantic segments. These segments not only increase computational and modeling complexity but also substantially degrade the robustness and reliability of recognition systems under real-world conditions[1,2,3]. For intelligent systems deployed in education, healthcare, and public service scenarios, such instability can critically hinder interactive reliability and operational robustness[4,5]. Therefore, developing recognition frameworks that maintain stability and semantic accuracy amid environmental and behavioral variability has become a central challenge in complex intelligent systems and human–machine interaction engineering.
Continuous sign language recognition (CSLR) has emerged as a core technology for enabling semantic-level understanding within intelligent systems. Its objective is to convert temporally continuous video sequences into ordered gloss units, bridging visual perception and linguistic comprehension. With the rapid advancement of deep learning[6,7], CSLR has evolved from early handcrafted feature-based pipelines[8,9] to end-to-end neural architectures[10,11,12,13], achieving significant gains in accuracy, robustness, and scalability. This progression marks a critical step toward constructing complex multi-modal systems capable of understanding, reasoning, and adapting to dynamic human communication. Consequently, CSLR is not only a frontier research topic in computer vision and language understanding but also a key enabler of resilient, human-centered intelligent engineering systems.
Existing learning-based CSLR methods have made significant strides using different modal data. However, RGB (red, green, and blue)-based CSLR methods exhibit limited performance in high dynamic range (HDR) scenarios. Event cameras[14,15], which offer advantages such as HDR and high temporal resolution[16,17], show promise for CSLR[18], particularly under extremely low-light conditions. Nevertheless, event cameras cannot capture color or fine-grained details, resulting in inferior performance under conventional conditions compared to RGB-based CSLR methods[18,19]. Most existing methods focus on modality-specific visual modeling, making them sensitive to input data and limiting their generalizability. Although multi-modal CSLR methods[19,20,21] can leverage the complementary strengths of different modalities, they face challenges due to rapidly increasing computational demands, which restrict their practical applicability. To this end, there is an urgent need for a unified modeling framework that can effectively leverage the complementary strengths of different modalities while ensuring strong robustness and efficiency, making it well-suited for diverse sign language recognition scenarios.
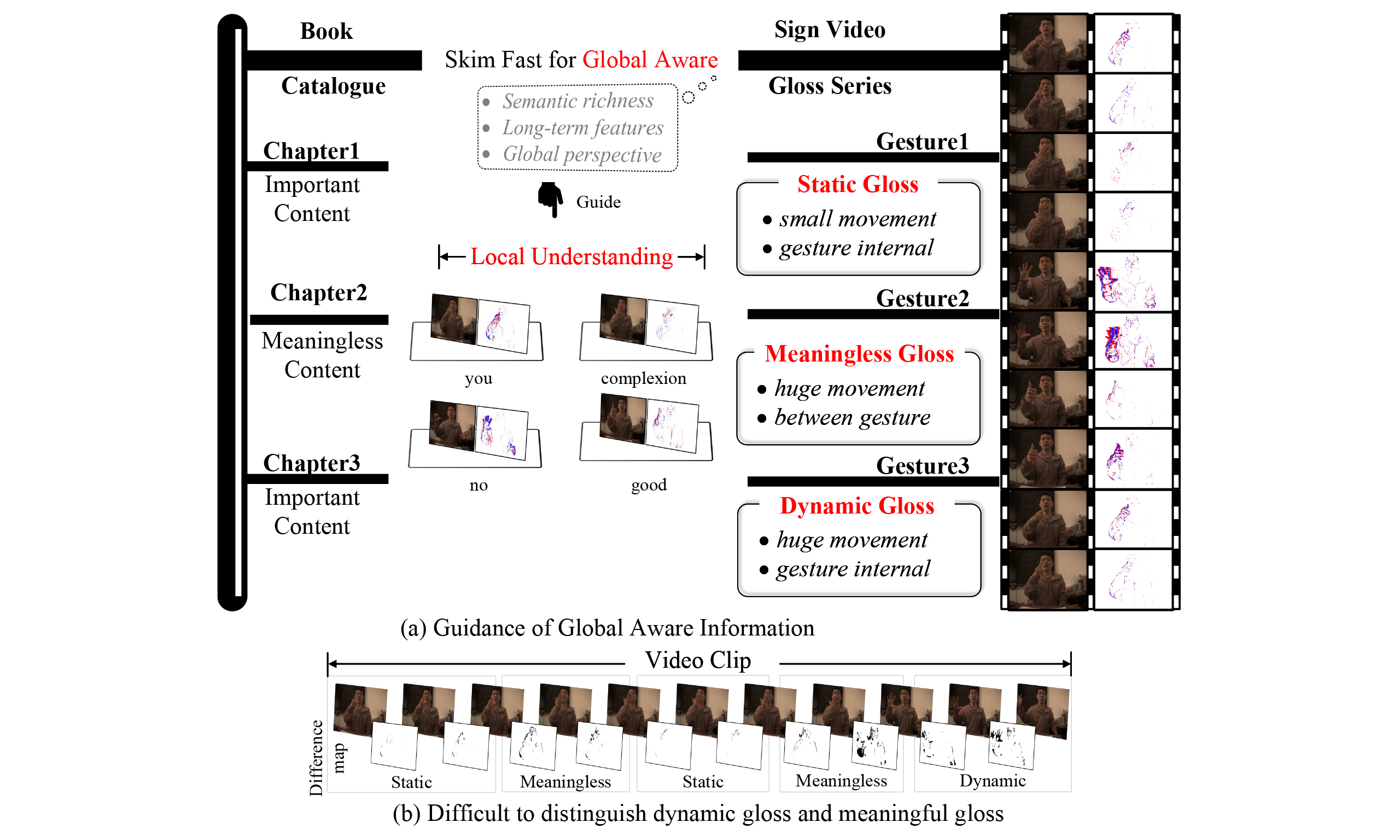
Sign language videos inherently involve complex temporal dynamics and global semantic structures[22,23,24], governed by unique grammatical rules, which pose significant challenges for CSLR. Most existing methods[20,21,25,26] adopt a two-stage architecture, incorporating global information only during temporal modeling. However, such methods fail to fully exploit high-level semantic context and lack mechanisms to leverage global semantics to guide local recognition, thereby limiting overall performance. Inspired by the reading habit of "Book-Chapter-Content", where readers first examine the table of contents to grasp the general structure and key chapters before engaging in detailed reading, a similar strategy can be applied to sign language video comprehension (Video-Gloss-Meaning). Specifically, the entire video is first rapidly scanned to capture global context, facilitating an understanding of the overall structure and gloss composition. This is followed by a detailed analysis of individual gesture components within each gloss. As illustrated in Figure 1, this strategy enables the model to better capture the contextual relationships between global structure and local details when processing sign language videos.
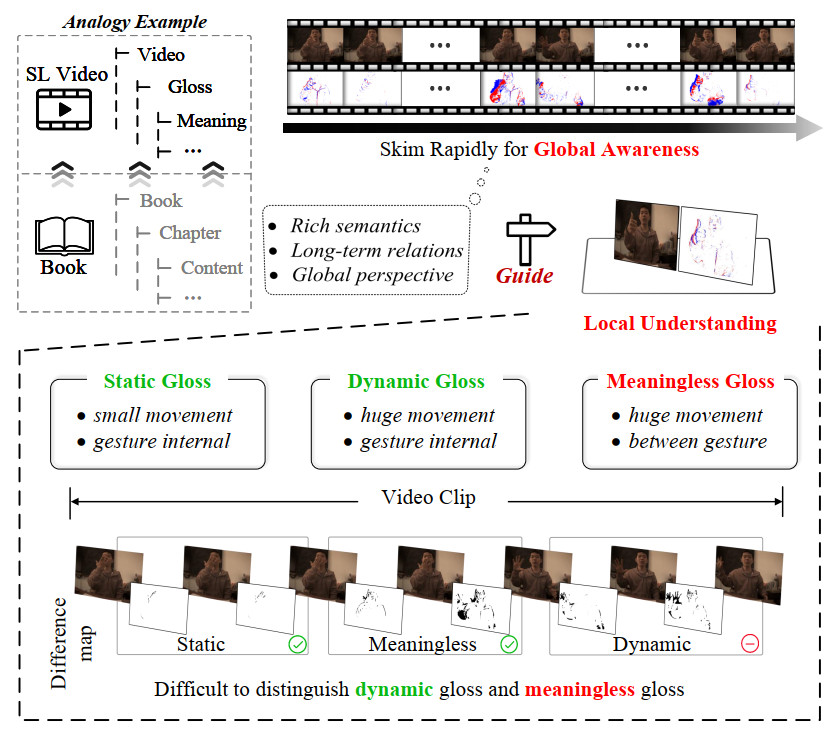
Figure 1. A brief illumination of the proposed method. Inspired by the reading habit of "Book-Chapter-Content", a heuristic strategy is adopted to first model global contextual awareness and then focus on local gloss understanding, enhancing the distinction between sign language gloss types. The data used in this figure is obtained from the EvCSLR open-source dataset, which is available at https://github.com/diamondxx/EvCSLR.
According to the grammatical structure of sign language, glosses in a sign language video can be categorized into three types: static, dynamic, and meaningless, as illustrated in Figure 1. Static glosses typically exhibit stable and well-defined hand shapes and spatial patterns, making them easier to distinguish from other gesture components in context and thus more reliably recognized. In contrast, dynamic glosses involve significant motion variations and rely heavily on contextual cues for semantic interpretation. Meaningless glosses, such as transitional movements or limb adjustments, do not carry semantic content but often share similar motion patterns with dynamic glosses. This ambiguity between appearance and semantics greatly increases the difficulty of accurately recognizing dynamic glosses, often resulting in redundant predictions or missed key gestures, which severely affects overall recognition accuracy. However, existing CSLR methods[27,28] often overlook this challenge and fail to effectively address the ambiguous boundaries between dynamic glosses and meaningless segments. As a result, non-semantic fragments introduce substantial interference, severely limiting the applicability of these methods in complex real-world scenarios.
Existing multi-modal CSLR methods[19,29] predominantly focus on modality fusion, where the primary optimization objective is to achieve cross-modal information collaboration through attention mechanisms. These approaches typically adopt multi-branch architectures, performing fusion at either the feature level or the decision level. They further enhance inter-modal consistency through alignment constraints or explicit weighting strategies. In essence, their central concern lies in how to effectively fuse different modalities. In contrast, our work targets a more fundamental issue in CSLR—semantic structure modeling. Specifically, we explicitly model video-level semantic structures through global context modeling. Moreover, an attention mechanism is introduced to distinguish among static semantic gestures, dynamic semantic gestures, and non-informative transitional movements. This design enables a collaborative optimization paradigm that integrates semantic structure modeling with gesture-type suppression, thereby improving semantic discrimination in CSLR.
To address these challenges, we propose GANet, a novel gloss-aware network with multi-modal robustness for accurate CSLR. GANet leverages global context modeling to effectively focus on critical spatiotemporal regions, enhancing attention to meaningful gestures while suppressing interference from meaningless segments. It demonstrates strong robustness across diverse input modalities. Specifically, we introduce a Global Context Modeling Module (GCMM) to efficiently capture overall content and long-term dependencies in sign language videos, enabling comprehensive global context modeling. Additionally, an auxiliary gloss length prediction (GLP) task is incorporated to explicitly guide the model to learn richer global information, further improving its understanding of entire sign language sequences. To emphasize meaningful gloss segments, we design a Gloss-Aware Module (GAM), which utilizes global context to enhance local gloss understanding and reinforce attention to semantically relevant gestures. Owing to GANet's flexible design, the model naturally adapts to various input modalities. Extensive cross-modal experiments on multiple sign language datasets (EvCSLR, PHOENIX14T, and EvSign) demonstrate that GANet consistently outperforms existing methods, highlighting its strong potential for intelligent sign language recognition and application systems.
In summary, the main contributions can be summarized as follows:
● We propose a novel CSLR network with multi-modal robustness that integrates global context modeling and emphasizes meaningful gloss gestures, thereby improving CSLR performance.
● We introduce a GCMM to extract global semantic information and capture long-term dependencies. Additionally, we design a GAM to focus attention on meaningful gloss features while suppressing non-contributory components.
● Experimental results on multiple multi-modal datasets show that the proposed method outperforms state-of-the-art approaches, consistently improving CSLR performance and demonstrating strong robustness across diverse modalities.
RELATED WORK
RGB-based sign language recognition
CSLR[30,31,32] is a weakly supervised task reliant on sentence-level annotations, requiring the model to extract visual features and align them with text length. Early methods utilized handcrafted features[33] to model spatial information, while temporal information was modeled using Hidden Markov Models[34]. Recent learning-based methods employ differentiable CTC loss functions[35] for result alignment, enabling end-to-end training. To enhance spatial feature extraction, many methods[36,37,38] use Convolutional Neural Networks (CNNs) as visual feature extractors. Oscar et al.[36] introduced a CNN+LSTM+HMM framework that captures robust spatiotemporal features. STMC[20] and CorrNet[26] focus on body trajectories, while SEN[39] employs self-attention modules to emphasize important areas. C2SLR[33] effectively models long-term temporal features by incorporating pre-trained joint heatmap information. Additionally, some studies explore integrating other visual modalities, such as skeleton[29,40,41] and depth data[42,43,44], to address the limitations of RGB input. Existing methods primarily focus on locally optimizing the extraction of visual features, overlooking the crucial global context information. In this paper, inspired by the human reading habit of "Book-Chapter-Content", we adopt a "global first and local later" strategy to explicitly extract global contextual semantics, thereby guiding a better understanding of local content.
Event-based sign language recognition
Event cameras can capture pixel intensity changes with microsecond-level precision and possess a HDR, enabling clearer motion detection in scenarios involving rapid movement or extreme lighting conditions. They provide rich information across both temporal and spatial dimensions. Event cameras have been widely applied in various vision tasks[45,46], including intensity image reconstruction[47,48], image restoration[49,50], and object detection[51]. Recently, several studies have integrated event cameras into isolated sign language recognition tasks[52,53,54,55]. Vasudevan et al.[53,54] introduced an event-based dataset for Spanish Sign Language and evaluated it using spiking neural networks, while Wang et al.[55] created a dataset for American Sign Language. Zhang et al.[18] presented the first large-scale event-based sign language dataset, EvSign, and designed a lightweight Transformer-based model to leverage the high temporal resolution of event data. Additionally, Jiang et al.[19] offered the EvCSLR dataset for CSLR, exploring the interaction between RGB and event modalities and proposing an innovative multimodal model. While these studies recognize and leverage the advantages of event data in sign language recognition, they typically design methods specific to the event modality, making them sensitive to different input modalities and lacking a unified multimodal adaptation approach. In this paper, we propose a method with high robustness across modalities, achieving exceptional performance in both event-based and other modalities.
METHOD
Overall architecture
As illustrated in Figure 2, the input to our framework is a video clip
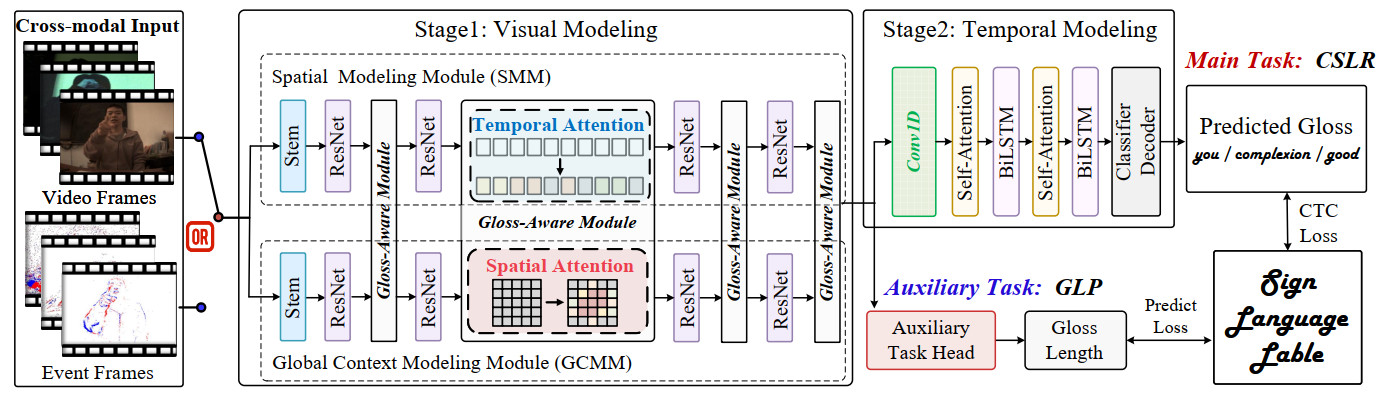
Figure 2. An overview of the proposed GANet. GANet processes multi-modal inputs (RGB or event-based data). It extracts features through a two-stage network and ultimately predicts the gloss sequence and its length. Additionally, an auxiliary task is designed to explicitly guide the network in learning global contextual information. The data used in this figure is obtained from the EvCSLR open-source dataset, which is available at https://github.com/diamondxx/EvCSLR.
Based on intuitive observations, we optimize the entire pipeline from the perspectives of global context and gloss awareness. To enable the network to explicitly establish global contextual relationships, we incorporate a GCMM during the visual modeling stage and design an auxiliary GLP task to explicitly guide the network toward a fundamental understanding of the overall content. To more accurately identify meaningful spatiotemporal regions, we propose a GAM, which leverages the global information from GCMM to enhance local understanding within the spatial modeling module (SMM), thereby improving gloss recognition accuracy and key region modeling capability.
In terms of network architecture, the overall framework is based on a dual-branch three-dimensional (3D) convolutional network with explicit semantic interaction. The backbone consists of four residual stages (layer1–layer4), with channel dimensions progressively set to 64, 128, 256, and 512, respectively, to hierarchically capture low-level spatial patterns and high-level semantic representations. In parallel, the GCMM follows an architecture-aligned but lightweight design, starting from an initial channel width of 16 and expanding to 16, 32, 64, and 128 across the four stages. This reduced configuration allows GCMM to efficiently encode long-range temporal semantics and video-level contextual information with minimal computational overhead. Feature interactions between SMM and GCMM are established at multiple stages through the proposed GAM, whereby global semantic cues extracted by GCMM are used to modulate local spatiotemporal features via attention-based fusion. This design enables global-to-local semantic guidance, allowing the network to emphasize gloss-relevant regions while suppressing irrelevant motion patterns. Together, the dual-branch architecture and multi-level semantic fusion ensure that both fine-grained spatial details and holistic contextual semantics are explicitly modeled within a unified and reproducible framework.
Global context modeling module
Humans typically develop a global semantic awareness when interpreting video content, which facilitates a coherent understanding of the overall narrative before focusing on critical details for local analysis. Compared to general video data, sign language videos exhibit greater motion complexity and stronger spatiotemporal-semantic coupling, making them more reliant on high-level semantic modeling and temporal information integration. Most existing studies focus on enhancing the extraction of visual features. Although some works have acknowledged the importance of global contextual information in CSLR tasks[25], they primarily emphasize temporal modeling and fail to explicitly capture global semantic context from a spatial perspective. This limitation causes models to over-rely on local segments during recognition, thereby restricting overall performance. To address this issue, we propose the GCMM, which effectively captures contextual semantics and strengthens the model's comprehension of global video content.
We design the GCMM to enhance the backbone network's ability to model global semantic structures, capture contextual information, and improve the understanding of overall video content. The architecture of GCMM is inspired by the SMM in terms of implementation; however, its modeling objectives and semantic focus are fundamentally different. While SMM targets fine-grained local spatial details, GCMM performs low-channel scanning across entire frames to extract high-level semantic patterns that span the full video. Despite these structural similarities, semantic decoupling is ensured through the following mechanisms: (1) a channel compression design that emphasizes core semantic structures over redundant details; and (2) a layer-wise fusion strategy where GCMM outputs serve as contextual regulators embedded within the backbone features, rather than forming a parallel processing branch. Since the evolution of sign language semantics depends not only on single-frame information but also on cross-frame continuity, temporal information is preserved alongside spatial modeling to construct a unified spatiotemporal semantic context.
However, structural design alone is insufficient to encourage the model to actively perceive global semantics. To further enhance global modeling capability, we introduce an auxiliary training task—GLP. This task leverages the annotated number of glosses in each video as a supervisory signal, guiding the model to explicitly learn the overall semantic structure. Rather than formulating GLP as a regression problem, we cast it as a multi-class classification task aimed at predicting the discrete distribution of gloss counts. This choice is motivated by three key factors: (1) classification is more stable and less sensitive to label noise or scale variations, leading to improved convergence; (2) the distribution of gloss counts in real-world corpora is inherently discrete, making classification better aligned with the data characteristics; and (3) similar count-based modeling strategies have shown strong performance in various semantic recognition tasks.
We adopt a cross-entropy loss to measure the discrepancy between the predicted and ground-truth gloss counts, as defined in Eq. 1. The GLP task requires no additional annotations and can be jointly optimized with the main objective, introducing no extra inference overhead. This approach enhances the model's ability to learn global context and strengthens its comprehension of the video content.
where
Although the overall structure of GCMM is inspired by dual-stream architectures such as the SlowFast network[56], the core objectives are fundamentally different. SlowFast focuses on modeling temporal frequency for action recognition, whereas GCMM is not designed for frequency modeling. Instead, it serves as a low-dimensional abstraction of cross-frame spatial semantics, regulating the attention span of the backbone network. This mechanism guides the main task toward key segments and high-value frames from a semantic perspective.
Gloss-aware module
Compared to general action recognition tasks, CSLR presents a significantly more complex challenge in high-level semantic modeling. While traditional action recognition focuses on classifying the overall action category of a video, CSLR demands a finer-grained understanding—requiring the model to not only capture the global semantic structure of the video but also accurately segment and align each gesture segment with its corresponding gloss. This capability is essential for handling complex semantic boundary transitions and gloss unit switching. To better understand and model the spatiotemporal structure in CSLR, we categorize sign language videos into three components based on motion patterns and semantic relevance, as illustrated in Figure 1: Static Gloss, Dynamic Gloss, and Meaningless Gloss. This categorization helps the model explicitly identify and prioritize semantically meaningful regions, reducing interference from irrelevant or redundant information.
● Static glosses: typically exhibit relatively stable hand shapes and positions, conveying clear and independent semantic meanings. Common examples include pronouns such as "I", "you", and "he". These signs involve limited motion and have well-defined boundaries, making them relatively easier to recognize.
● Dynamic glosses: involve prominent temporal variations and are often used to express verbs, directional movements, or compound semantic structures (e.g., "make a phone call", "walk over"). Their recognition requires stronger contextual modeling due to the complexity of motion patterns and semantic transitions.
● Meaningless glosses: consist mainly of transitional movements or natural body adjustments. Although they may appear as large-scale motions, they lack explicit semantic content and are easily confused with dynamic glosses, making them a major source of noise that degrades recognition accuracy.
As shown in Figure 3, we provide a detailed visualization of the differences among three types of glosses in continuous sign language video streams. Specifically, we select three representative examples to illustrate their distinct motion patterns and semantic attributes. For static glosses, we use the example "very", which is characterized by minimal temporal motion and a stable hand configuration that conveys clear semantic meaning. For dynamic glosses, we choose "age", which involves a sequence of pronounced and continuous hand movements, representing a more complex temporal structure. Meaningless glosses are exemplified by transitional frames between two meaningful glosses, which exhibit significant motion but lack semantic content. To better highlight these differences, we present both RGB video frames and corresponding event-based frames for each example. The comparison reveals that static glosses tend to maintain spatial consistency, dynamic glosses show strong temporal evolution, and meaningless glosses often display large motion without meaningful structure. This visualization intuitively demonstrates the semantic and temporal distinctions across gloss types and modalities, and underscores the modeling challenges inherent to each category.
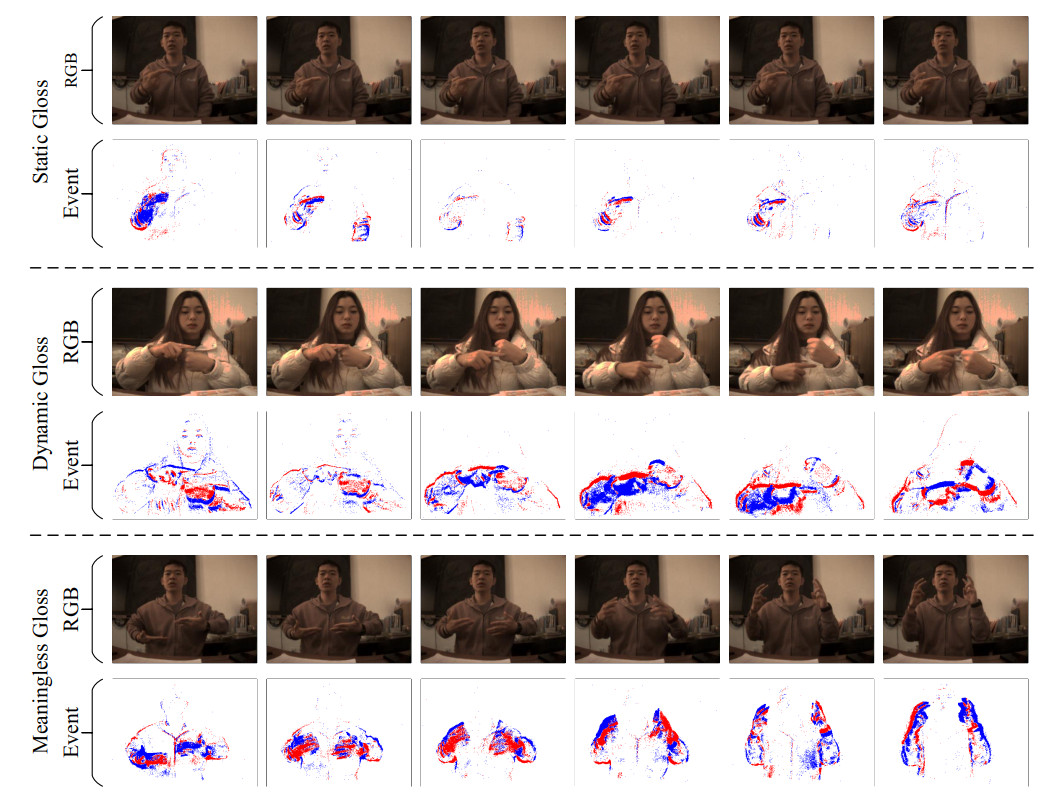
Figure 3. Visualization of the three gloss types. We provide visual examples of static, dynamic, and meaningless glosses across both RGB and event modalities, offering an intuitive comparison of their visual characteristics and modality-specific distinctions. The data used in this figure is obtained from the EvCSLR open-source dataset, which is available at https://github.com/diamondxx/EvCSLR.
To enhance the model's ability to capture key sign language segments within complex semantic structures, we propose the GAM, as illustrated in Figure 4. This module explicitly guides the network to focus on spatiotemporal regions carrying semantic information while suppressing over-responses to meaningless gesture segments. GAM is designed to improve discrimination among different sign types, namely static, dynamic, and meaningless glosses, thereby boosting overall recognition accuracy and contextual modeling.
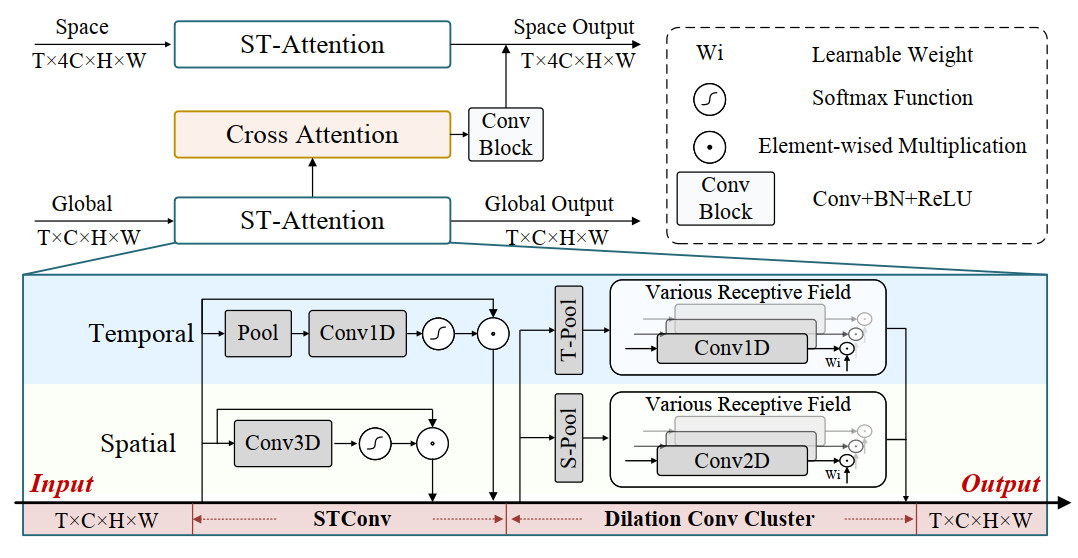
Figure 4. The architecture of the proposed GAM. Features from both branches are processed through the spatiotemporal attention (ST-Attention) block to emphasize key spatiotemporal regions.
Specifically, GAM incorporates a lightweight spatiotemporal convolution (STConv) applied to shallow feature maps to jointly capture local spatial and temporal attention patterns, thereby extracting preliminary gloss-level cues. Subsequently, a multi-scale dilated convolution cluster expands the receptive field and fuses contextual information across different scales, enhancing the modeling of dynamic structures within gloss regions. To overcome the limitations of manually selecting scales, we further adopt an adaptive fusion mechanism that learns dynamic weights to flexibly integrate multi-scale features, enabling effective adaptation to diverse gloss durations and motion patterns. Finally, GAM leverages global context features generated by the GCMM branch to produce semantic guidance features, which are fused with backbone features to steer the network toward a better understanding of local key gestures. This global-to-local semantic guidance strengthens semantic responses along spatiotemporal dimensions, suppresses irrelevant interference, and enriches local representations by incorporating spatial awareness cues. In this way, GAM achieves dynamic semantic enhancement from global context to local regions, improving both global perception and fine-grained gesture discrimination, thereby increasing robustness and recognition accuracy in complex continuous sign language scenarios.
EXPERIMENTS
Dataset and preprocessing
We conduct extensive experiments on three datasets: EvCSLR[19], EvSign[18], and PHOENIX14T[57]. EvCSLR is a recently proposed Chinese sign language dataset with real event data, comprising 2, 685 videos and 424 vocabulary items. For experimental reproducibility, it is divided into 2, 200 training samples, 240 validation samples, and 245 test samples. The dataset is based on 242 commonly used daily sentences and features complex backgrounds and challenging lighting conditions. EvSign is another recently introduced Chinese sign language dataset, containing 6, 773 videos and 1, 387 vocabulary items, with 5, 570 training samples, 553 validation samples, and 650 test samples. It provides more consistent annotations for synonymous vocabulary, exclusively includes event modalities, and has undergone dedicated sparsification processing. PHOENIX14T is a widely used German sign language dataset, comprising 1, 085 vocabulary items, with 7, 096 training samples, 519 validation samples, and 642 test samples. To demonstrate the robustness of our method across different modalities, we generate corresponding event data using the event simulator Video-to-Events (V2E)[58].
Implementation details
The proposed method is implemented using PyTorch, and all experiments are conducted on a single NVIDIA V100 Graphics Processing Unit (GPU) with 32 GB memory. To ensure reproducibility, a fixed random seed of 3407 is used and consistently applied to PyTorch, NumPy, and Compute Unified Device Architecture (CUDA) operations to eliminate stochastic variation across runs. During training, the batch size is set to 2, while a batch size of 1 is adopted for validation and testing to ensure stable evaluation under long video sequences and memory constraints. All models are trained for 100 epochs under the same optimization schedule to guarantee fair comparisons across different methods. For data preprocessing, all input video frames are first resized to 256 × 256. During training, data augmentation includes random spatial cropping to 224 × 224, horizontal flipping with a probability of 50%, and random temporal scaling within ±20%. The temporal scaling operation randomly stretches or compresses the frame sequence length within the specified range to improve robustness to signing speed variations. During validation and testing, frames are resized to 256 × 256 and then center-cropped to 224 × 224, without any stochastic augmentation, ensuring deterministic evaluation. The training objective consists of joint optimization of the main CSLR task and an auxiliary GLP task. Specifically, the main task is supervised using the Connectionist Temporal Classification (CTC) loss, which enables effective sequence-level learning without requiring explicit frame-level alignment between video frames and gloss labels. To enhance global semantic modeling, the auxiliary GLP task predicts the total number of glosses in the input video sequence. This task is formulated as a multi-class classification problem and optimized using cross-entropy loss. The loss weight ratio between CTC and GLP is set to 1:1. The auxiliary task acts as a regularization signal to strengthen global context modeling while introducing no additional computational overhead during inference. For optimization, the Adaptive Moment Estimation (Adam) optimizer is employed with an initial learning rate of 1 × 10-4 and a weight decay of 1 × 10-4. Instead of relying solely on the default Adam update rule, we adopt a step-based learning rate scheduler to explicitly control the training dynamics. The learning rate is decayed at the 10th and 20th epochs following a predefined step schedule. This strategy replaces the previously ambiguous description of an "adaptive update schedule" and ensures clear reproducibility of the training process. For decoding, we adopt a CTC beam search decoder during inference. Specifically, we use CTCBeamDecoder with a beam width of 10, a blank token index consistent with the vocabulary definition, and 10 parallel decoding processes to accelerate beam search computation. This decoding configuration is consistently applied across all experiments to maintain fair evaluation. All comparative experiments are conducted under identical optimization settings and training schedules unless otherwise specified. For baseline methods, we strictly follow the official configurations and publicly available implementations of the original papers to ensure fair and unbiased comparisons.
Evaluation metrics
We use Word Error Rate (WER) as a metric to measure the accuracy of CSLR. WER is calculated as the sum of the minimum substitutions (#sub), insertions (#ins), and deletions (#del) needed to transform the predicted sentence into the reference sentence, divided by the total number of glosses in the reference (#glosses in reference). A lower WER indicates better performance. The formula is expressed as follows:
Comparisons with state-of-the-art methods
Evaluation on EvCSLR dataset
Table 1 summarizes the performance comparison between the proposed GANet and several representative CSLR methods from recent years on the EvCSLR dataset, evaluated separately on RGB and event modalities. Overall, GANet achieves the lowest WER across all settings and clearly surpasses the latest existing methods. In the RGB modality, GANet achieves WERs of 20.92% on the development set and 17.31% on the test set, corresponding to absolute gains of 4.98% and 6.19% over the previous best results (Dev: 25.90%, Test: 23.50%). These substantial improvements indicate that our model is more effective in handling appearance variations under natural illumination, complex handshape and motion patterns, and sentence-level contextual dependencies. GANet also demonstrates strong performance in the event modality. It achieves WERs of 17.24% on the development set and 16.75% on the test set, outperforming existing results (Dev: 19.80%, Test: 18.40%). The 1.65% absolute improvement on the test set further confirms that GANet is well-suited to the high temporal resolution and HDR inherent in event data. It is worth noting that event-based methods generally outperform RGB counterparts on this dataset. This trend aligns with the sensing characteristics of event cameras, which excel in capturing rapid motion and low-light dynamics. Since sign gestures often involve fast and fine-grained movements, event data provide more expressive cues for motion boundaries and dynamic trajectories. Despite this stronger overall competitiveness in the event modality, GANet still achieves the best performance, demonstrating that its global-aware and type-aware modeling mechanisms effectively adapt to the temporal and semantic structures of different visual modalities. In summary, GANet exhibits strong cross-modal generalization and robustness, maintaining consistently high recognition performance across both RGB and event inputs. These results validate the effectiveness of our method and highlight the importance and generality of guiding local segment recognition with global semantic context in complex sentence-level sign language understanding.
Comparison results for CSLR on the EvCSLR dataset
| Method | Dev (RGB) | Test (RGB) | Dev (Evs.) | Test (Evs.) | ||||
| del/ins | WER ↓ | del/ins | WER ↓ | del/ins | WER ↓ | del/ins | WER ↓ | |
| VAC[59] | 15.0/1.2 | 26.80% | 13.5/2.2 | 26.30% | 10.7/0.9 | 21.20% | 11.2/1.4 | 20.50% |
| TLP[60] | 12.7/1.8 | 30.50% | 17.7/0.9 | 28.80% | 9.3/0.8 | 21.90% | 10.6/1.6 | 20.70% |
| SEN[39] | 11.5/1.6 | 11.1/1.4 | 24.60% | 9.8/1.0 | 22.90% | 9.2/2.0 | 22.30% | |
| CorrNet[26] | 20.0/0.6 | 36.10% | 20.1/0.6 | 36.40% | 14.2/0.6 | 29.60% | 14.6/1.4 | 28.50% |
| EvCSLR[19] | —/— | 28.50% | —/— | —/— | —/— | |||
| SignGraph[19] | 21.7/0.4 | 35.73% | 22.0/0.5 | 34.21% | 16.5/0.4 | 29.79% | 18.1/0.6 | 29.65% |
| Swin-MSTP[61] | —/— | 37.40% | —/— | 37.60% | —/— | 33.40% | —/— | 35.70% |
| Ours | 7.3/1.8 | 20.92% | 6.1/2.2 | 17.31% | 5.3/1.7 | 17.24% | 6.3/1.6 | 16.75% |
As shown in Figure 5, additional visual comparisons are presented to thoroughly illustrate the recognition performance of different modalities under low-light conditions. Owing to its high temporal resolution and sensitivity to motion cues, the event modality can clearly capture gesture edge contours and details in motion-blurred regions, effectively mitigating visual blur and information loss caused by insufficient lighting. This characteristic enables the model to accurately capture key gesture movements even in challenging environments, leading to improved recognition accuracy. Coupled with our designed GCMM and GAM, the rich motion information provided by the event modality further enhances the model's overall spatiotemporal semantic perception and local detail focus. By guiding local understanding through global information, GANet effectively integrates the advantages of multiple modalities, achieving robust performance in complex real-world scenarios. These visualizations not only validate the practical potential of the event modality but also fully demonstrate the superiority of our method in cross-modal semantic fusion and dynamic key-region capturing, further highlighting GANet's comprehensive strength in advancing CSLR performance.
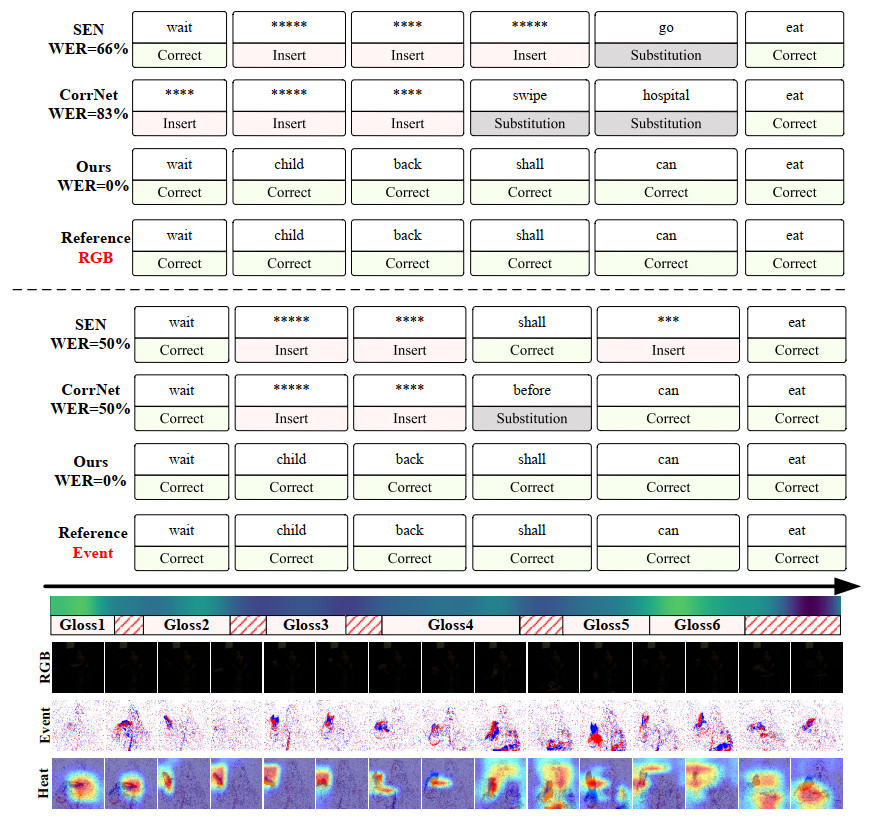
Figure 5. Visualization of recognition results. It presents the results of the proposed method on RGB and event modalities, respectively. "Correct" indicates correct predictions, while other cases correspond to incorrect predictions. The symbol "*" denotes an auxiliary gloss placeholder introduced during the WER alignment process, which is used to represent insertion operations when aligning predicted sequences with reference sequences. The bottom row shows attention heatmaps from the backbone network output generated by Grad-CAM[62]. The data used in this figure is obtained from the EvCSLR open-source dataset, which is available at https://github.com/diamondxx/EvCSLR.
Evaluation on EvSign and PHOENIX14T datasets
Table 2 presents the performance of our method on the EvSign and PHOENIX14T datasets, along with comparisons to the latest methods. On the EvSign dataset, the event data exhibit strong sparsity, which motivated us to apply a targeted lightweight adjustment to the network. We removed redundant components that contribute minimally in this setting and retained only the core modeling units to avoid overfitting and unnecessary computation. Despite this streamlined design, our method still achieves the best performance on the dataset, with WERs of 28.93% on the validation set and 27.23% on the test set. The 2.72% improvement on the test split further demonstrates that our global context modeling and GAM can effectively capture key semantic cues even under extremely sparse event inputs, enabling reliable recognition in low-quality data conditions. On the PHOENIX14T dataset, we follow the same RGB configuration used in EvCSLR and employ a synthetic event generation pipeline for the event modality. Although the generated event data do not fully reflect the dynamic advantages of event sensors—being constrained by the original frame rate, motion blur, and temporal inconsistencies—GANet still achieves competitive or superior results across both modalities. In the RGB modality, GANet attains WERs of 19.05% and 20.36% on the validation and test sets, respectively. While it does not consistently surpass all existing state-of-the-art methods, the results remain highly competitive, demonstrating that our method can effectively model global-local semantic context without relying on RGB-specific priors. This also reflects the "performance saturation" on Phoenix14T-RGB, where differences among top methods are small and further improvements often require task-specific assumptions or complex structural designs. In the event modality, GANet remains competitive with WERs of 23.32% and 23.66% on the validation and test sets, respectively, showing that the model maintains good adaptability and robustness even when the event inputs are of limited quality. Overall, across EvSign and PHOENIX14T—two datasets with distinct modality characteristics and varying data quality—GANet consistently delivers stable and reliable performance. Whether facing sparse event data, cross-task distribution shifts, or limitations in synthetic event generation, our method achieves results superior to those of existing methods. These findings confirm the generality of the proposed global semantic guidance and type-aware modeling strategies, and further demonstrate that GANet possesses strong multimodal and multi-scenario generalization ability, laying a solid foundation for more complex CSLR applications in the future.
Comparison results for CSLR on the EvSign and PHOENIX14T datasets
| Method | EvSign (Evs.) | PHOENIX14T (Evs.) | PHOENIX14T (RGB) | |||
| Dev WER ↓ | Test WER ↓ | Dev WER ↓ | Test WER ↓ | Dev WER ↓ | Test WER ↓ | |
| VAC[59] | 30.84% | 30.71% | 24.99% | 24.77% | 21.50% | 22.10% |
| TLP[60] | 32.59% | 32.68% | 24.81% | 24.60% | 19.40% | 21.20% |
| SEN[39] | 33.34% | 32.71% | 24.63% | 24.51% | 19.30% | 20.70% |
| CorrNet[26] | 29.98% | 29.95% | 24.57% | 24.55% | 18.90% | 20.50% |
| EvSign[18] | 29.95% | 23.89% | — | — | ||
| SignGraph[63] | 29.60% | 24.34% | 19.21% | |||
| ONLINE[64] | — | — | — | — | 22.20% | 22.10% |
| CORE[65] | — | — | — | — | — | 21.60% |
| Ours | 28.93% | 27.23% | 23.32% | 23.66% | 20.36% | |
Ablation study
Ablation analysis of core modules
To validate the effectiveness of the proposed method, we conduct systematic ablation experiments on the EvCSLR dataset to analyze the contribution of each key component. The results are summarized in Table 3. It is important to note that, in this ablation study, each module is individually introduced into the baseline model rather than incrementally stacked, in order to explicitly evaluate its standalone effect.
Core module ablation study on the EvCSLR dataset
| Setting | Dev | Test | ||
| del/ins | WER | del/ins | WER | |
| Baseline | 9.8/1.0 | 22.90% | 9.2/2.0 | 22.30% |
| w/GCMM | 8.6/1.6 | 20.00% | 9.3/1.7 | 20.59% |
| w/GLP | 8.4/1.0 | 19.50% | 9.5/1.2 | 20.03% |
| w/GAM | 9.0/1.0 | 20.92% | 9.1/1.0 | 19.23% |
| Ours | 5.3/1.7 | 17.24% | 6.3/1.6 | 16.75% |
Specifically, introducing the GCMM alone consistently reduces the WER on both the development (Dev) and test (Test) sets, demonstrating its effectiveness in capturing long-range temporal dependencies and global semantic information. However, since GCMM operates without explicit semantic supervision, its performance gain remains moderate. When the GLP auxiliary task is added to the baseline, the model achieves a more pronounced improvement. This is because GLP provides direct global-level supervision by constraining the predicted gloss sequence length, which effectively regularizes the temporal modeling process and enhances the network's ability to learn the overall semantic structure of continuous sign sequences.
The GAM is evaluated as another independent component. GAM aims to leverage global contextual information to reweight local spatiotemporal features, thereby guiding the network's attention toward semantically meaningful regions. As shown in Table 3, incorporating GAM alone still yields a clear improvement over the baseline on both the Dev and Test sets, confirming its effectiveness in enhancing local understanding. However, compared with the GLP setting, GAM exhibits a slightly higher WER on the Dev set. This behavior can be attributed to the fact that GAM does not introduce additional supervisory signals, and its effectiveness depends on the quality and stability of the global context representation. In the absence of explicit global semantic constraints, minor attention shifts or semantic redundancy may occur, particularly on the Dev set, leading to limited performance fluctuations. Importantly, these fluctuations do not indicate a degradation relative to the baseline, but rather reflect the different optimization characteristics of auxiliary supervision vs. feature-level guidance.
Finally, when GCMM, GLP, and GAM are jointly integrated into a unified framework, the model achieves the best performance across all evaluation metrics. In this setting, GLP provides stable global semantic supervision, GCMM models long-range contextual dependencies, and GAM effectively injects reliable global information into local spatiotemporal representations. Their complementary roles enable the network to balance global semantic understanding with fine-grained local modeling, resulting in significant and consistent improvements on both the Dev and Test sets. These results clearly demonstrate the synergistic benefits of the proposed components and validate the effectiveness and robustness of the overall architecture for CSLR.
Analysis of global context information
In Table 4, we conduct a comprehensive evaluation of various design choices for the GCMM and the GLP auxiliary task. Regarding receptive field configuration, the experimental results indicate that increasing the spatial convolutional kernel size does not lead to performance improvements; in some cases, it even results in slight degradation. This may be attributed to the spatial concentration of gesture regions in sign language videos, where an overly large receptive field introduces additional background noise and weakens the effectiveness of global semantic modeling. For the design of the GLP auxiliary task, we investigate two types of prediction heads: a lightweight multi-layer perceptron (Simple Head) and a more complex head that incorporates attention mechanisms to enhance contextual modeling (Complex Head). The results demonstrate that the Simple Head consistently provides more stable and effective supervision for learning global semantic representations. Due to its limited capacity, the Simple Head primarily captures coarse, video-level semantic statistics, which align well with the intended role of the GLP task as a global structural constraint. In contrast, although the Complex Head has stronger modeling capacity, it tends to learn overly detailed high-level temporal and contextual features that partially overlap with the semantic representations already modeled by the backbone network and GCMM. As a result, the semantic guidance provided by the GLP task becomes less effective, leading to inferior performance despite the increased structural complexity. These results indicate that, for auxiliary supervision in CSLR, the clarity and stability of the supervisory signal are more important than additional architectural complexity. Designing auxiliary tasks to deliver consistent and well-aligned global guidance is therefore preferable to introducing potentially interfering high-level features.
Comparison of various GCMM settings on the EvCSLR dataset
| Kernel size | Prediction head type | Dev | Test |
| 3 × 3 × 3 | Simple | 19.00% | 19.87% |
| 1 × 3 × 3 | Simple | 17.24% | 16.75% |
| 1 × 5 × 5 | Simple | 21.76% | 18.99% |
| 1 × 3 × 3 | Complex | 19.92% | 20.99% |
Analysis of GAM
In Table 5, we explore the impact of different GAM components. Removing STConv leads to a slight performance drop, indicating that simple dot-product attention is effective in capturing the importance distribution. Parallel connections of convolutions with different dilation rates, compared to serial connections, more effectively aggregate multi-scale information. Additionally, channel attention further enables global context information to guide local understanding more effectively.
Analysis of each component of the GAM on the EvCSLR dataset
| STConv | C-ATTN | ConvCluster | Dev | Test |
| √ | parallel | 20.42% | 20.42% | |
| √ | √ | serial | 19.83% | 19.83% |
| √ | parallel | 18.41% | 18.41% | |
| √ | √ | parallel | 17.24% | 16.75% |
More visualization of feature heatmaps
As shown in Figure 6, we employed Gradient-weighted Class Activation Mapping (Grad-CAM)[62] to visualize feature responses at different network layers, providing an intuitive illustration of the model's attention mechanisms during spatiotemporal feature extraction. The results demonstrate that as the network deepens, the model increasingly focuses on key semantic regions, while its responses to irrelevant backgrounds and noise diminish, confirming the effectiveness of the GCMM in extracting core semantic information. Furthermore, we showcase the method's robustness under varying lighting conditions—including low-light scenarios—and across multi-modal inputs (RGB or event modalities), indicating the model's stable capability to capture crucial gesture edges and dynamic details, thus reflecting its strong cross-modal adaptability. Finally, for the GAM, we provide detailed heatmap visualizations of its temporal feature outputs, clearly illustrating how global semantic guidance effectively enhances the focus on critical local gesture segments. This evidences the module's pivotal role in steering local understanding and improving recognition accuracy. Overall, these visualization analyses not only validate the rationality of each module's design but also enhance the interpretability of the model's semantic comprehension process, strongly supporting the effectiveness and advancement of the proposed method.
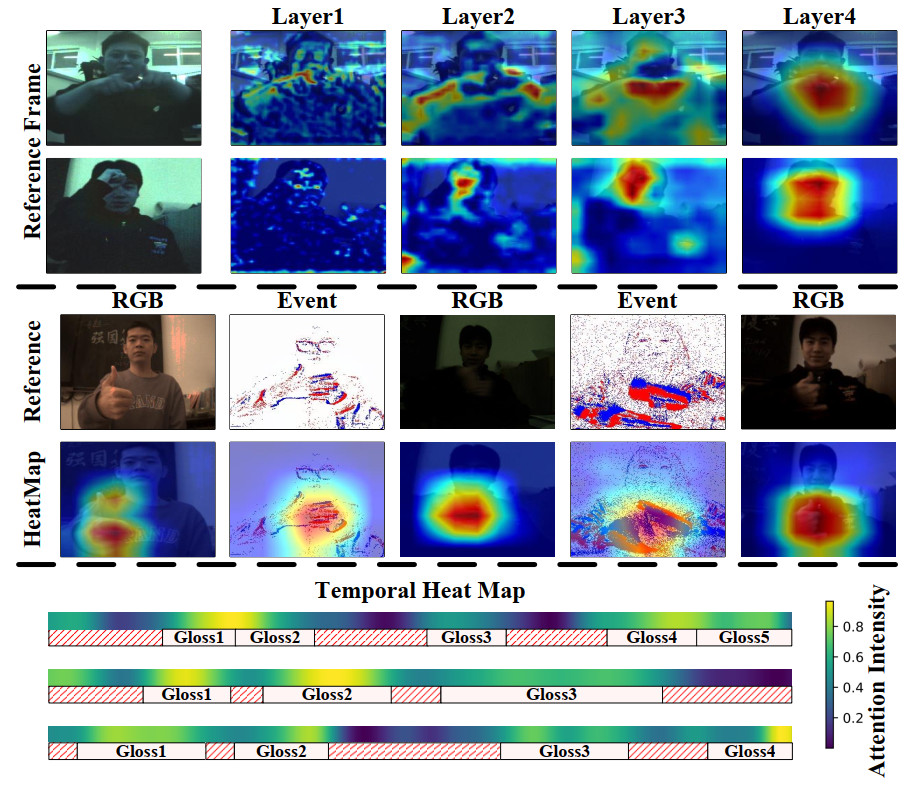
Figure 6. Visualization of feature heatmaps using Grad-CAM[62]. The top panel displays the attention distribution across different layers, the middle panel displays the attention distribution across different modalities, and the bottom panel displays the attention distribution over the temporal dimension. The data used in this figure is obtained from the EvCSLR open-source dataset, which is available at https://github.com/diamondxx/EvCSLR.
More analysis of redundancy in sign language
As shown in Figure 7, we further conduct a quantitative analysis of temporal redundancy in sign language videos to substantiate the design motivation and necessity of the proposed GAM. In this experiment, the x-axis denotes the proportion of video frames retained from the original input sequence during the testing stage, where frames are uniformly sampled, while the y-axis represents the relative WER, defined as the WER obtained under partial-frame input divided by the WER achieved using the full video sequence. This relative metric is adopted to explicitly measure performance degradation caused by discarding a certain proportion of frames, rather than to report absolute recognition accuracy. As observed from the results, when a reasonable proportion of frames is retained, the relative WER increases only marginally compared to the full-frame setting. This indicates that removing a substantial portion of frames does not immediately lead to severe performance deterioration, revealing a high degree of temporal redundancy inherent in continuous sign language videos. In other words, many frames contribute limited semantic information and primarily introduce redundant or transitional content. These observations confirm that not all frames are equally informative for semantic understanding, and effective recognition relies more on a subset of key spatiotemporal segments that carry discriminative gloss-level information. Consequently, explicitly identifying and emphasizing such semantically salient regions becomes crucial for improving recognition robustness. Motivated by this insight, the proposed GAM leverages global contextual cues to guide the network's attention toward frames with higher semantic relevance, while suppressing responses to redundant or less informative content. Overall, this redundancy analysis does not suggest that aggressive frame removal improves recognition performance, but rather demonstrates the uneven semantic contribution of video frames. It provides empirical evidence supporting the necessity of semantic-aware modeling in CSLR and highlights the role of GAM in effectively integrating global and local semantics under full-input conditions.
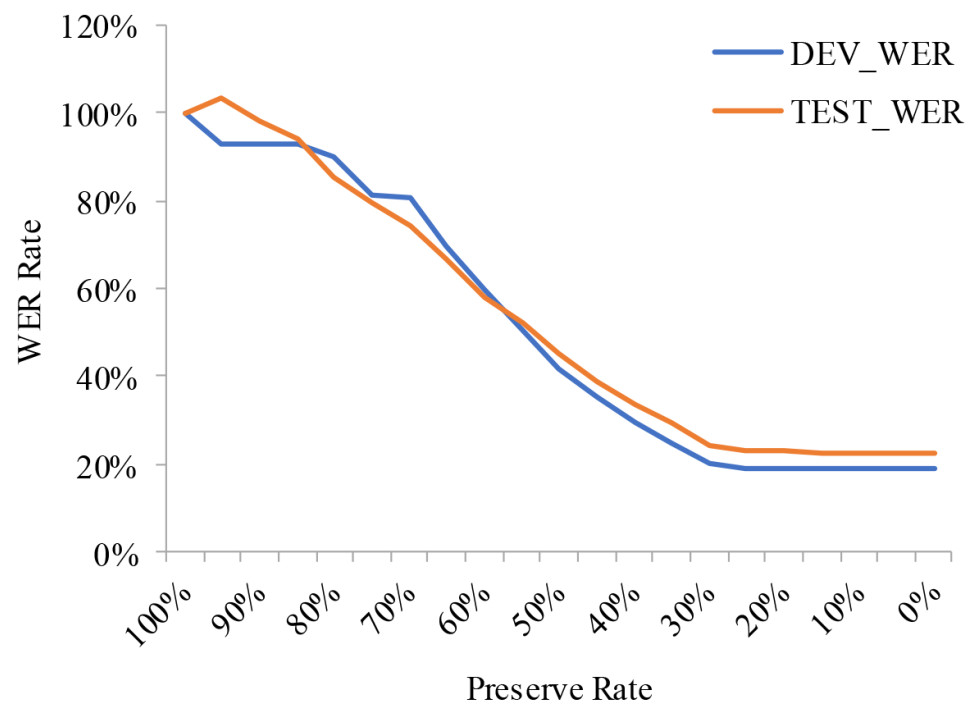
Figure 7. Analysis of Redundancy in Sign Language Videos. The x-axis denotes the proportion of randomly retained image frames from the input sequence, while the y-axis represents the ratio of the WER obtained using the reduced frame set to that obtained using all frames.
Efficiency evaluation
In addition to recognition accuracy, we further analyze the computational complexity and practical deployment characteristics of the proposed method. Table 6 reports a comprehensive comparison of inference time, GPU memory consumption, and floating-point operations (FLOPs). All measurements were conducted under identical hardware and software settings to ensure a fair comparison.
Efficiency metrics comparison of different methods
| Method | Times (s) | VRAM (GB) | FLOPs (GFlops) |
| VAC | 0.04 | 4.7 | 87.86 |
| SMKD | 0.04 | 4.7 | 87.85 |
| TLP | 0.06 | 4.8 | 88.25 |
| SEN | 0.05 | 4.9 | 89.03 |
| CorrNet | 0.04 | 5.1 | 90.06 |
| EvCSLR | 0.15 | 4.7 | 619.73 |
| Ours | 0.07 | 3.9 | 115.46 |
As shown in Table 6, our method achieves a favorable balance between performance and efficiency. Compared with conventional RGB-based baselines such as VAC, SMKD, TLP, and SEN, the method introduces moderate computational overhead due to additional global context modeling and gloss-aware fusion. However, this increase remains limited and well controlled: the method requires only 0.07 seconds per inference and 115.46 GFLOPs, which is lower than that of multi-modal methods such as EvCSLR, which rely on high-resolution temporal event streams and typically incur higher computational costs (over 600 GFLOPs). Notably, despite incorporating dual-branch modeling, our framework exhibits even lower GPU memory usage than most RGB baselines, demonstrating the effectiveness of the lightweight GCMM design.
From a scalability perspective, the proposed architecture is modular and extensible. Both the GCMM and GAM are designed as plug-and-play components that can be seamlessly integrated into standard 3D CNN-based visual backbones without altering the inference pipeline. Since the model relies solely on RGB or event input and does not require auxiliary modalities or external annotations at inference time, it can be readily extended to other large-scale sign language datasets or adapted to different deployment scenarios. Moreover, the compressed channel configuration of the GCMM enables the model to scale to longer video sequences while maintaining manageable growth in memory and computational cost.
Regarding real-world deployment, the proposed method maintains a practical inference speed and memory footprint on a single GPU, making it suitable for offline batch processing and near-real-time applications after standard engineering optimizations. The absence of additional post-processing steps and the unified end-to-end architecture further facilitate deployment in realistic sign language understanding systems.
Overall, these results indicate that the proposed method not only improves recognition accuracy but also maintains competitive efficiency and scalability, offering a practical solution for real-world CSLR.
Stability analysis
To further evaluate the reliability and stability of the proposed method, we conduct additional experiments using multiple random seeds. Specifically, we retrain the model three times with different random seeds across multiple datasets and report the average WER along with the corresponding variance for both the development and test sets. All experiments strictly follow the same training schedule, optimization settings, and decoding configurations.
As shown in the Table 7, the performance variance across different seeds remains consistently low on all evaluated datasets and modalities. In particular, PHOENIX14T exhibits extremely small variance, indicating highly stable convergence behavior. Although slightly larger fluctuations are observed for EvCSLR and EvSign, the magnitude of variation remains limited and does not affect the overall performance ranking or comparative conclusions.
Stability experiments on different datasets
| Dataset | Dev WER | Test WER | ||
| Average | Variance | Average | Variance | |
| EvCSLR (RGB) | 21.06 | 0.016 | 17.76 | 0.228 |
| EvCSLR (Evs.) | 17.32 | 0.006 | 17.36 | 0.316 |
| PHOENIX14T (RGB) | 19.05 | 0.001 | 20.50 | 0.016 |
| PHOENIX14T (Evs.) | 23.37 | 0.005 | 23.56 | 0.008 |
| EvSign (Evs.) | 29.21 | 0.060 | 27.71 | 0.241 |
Importantly, no systematic performance drift is observed across different initializations, suggesting that the proposed architecture and optimization strategy provide stable training dynamics. These results demonstrate that the improvements reported in the main experiments are not attributable to favorable random initialization, but instead reflect consistent and reproducible gains. This additional analysis strengthens the statistical reliability of our findings while remaining consistent with standard evaluation protocols in the CSLR literature.
CONCLUSIONS
This paper presents GANet, a multimodally robust framework for CSLR, designed to enhance both global context modeling and the recognition of key gestures. To address the limitations of existing methods in capturing global semantics, we introduce the GCMM, which compresses semantic channels to effectively capture long-range dependencies and improve semantic consistency. Additionally, we incorporate a GLP auxiliary task to explicitly guide the model in learning stable and comprehensive global representations. Building on this foundation, we propose the GAM, which leverages attention mechanisms and multi-scale receptive fields to focus the model on semantically valuable regions, thereby enhancing the responsiveness of local gestures to contextual cues. Furthermore, GANet exhibits inherent cross-modal adaptability, maintaining consistent performance across diverse input modalities such as RGB and event streams. Extensive experiments conducted on standard sign language datasets, including EvCSLR, EvSign, and PHOENIX14T, show that GANet outperforms state-of-the-art methods. These results demonstrate its strong capability in semantic modeling and multimodal robustness, indicating its potential for intelligent sign language recognition and application systems.
DECLARATIONS
Authors' contributions
Made substantial contributions to the conception and design of the study and performed data analysis and interpretation: Chu, Q.; Wang, Y.
Conducted the literature survey, synthesized the Special Issue papers, and drafted the initial manuscript: Chu, Q.; Xu, S.; Wang, Y.; Zhang, Y.; Guo, Q.
Provided critical revision of intellectual content: Qin, H.; Jiang, Y.
Availability of data and materials
The EvCSLR dataset and related files are openly available in the GitHub repository at https://github.com/diamondxx/EvCSLR under the MIT License[19]. This repository, developed by Wang, Y., provides the necessary data and should be properly cited in the references list of any related publication[19]. For more information, visit the GitHub repository.
AI and AI-assisted tools statement
Not applicable.
Financial support and sponsorship
This work was supported by the National Natural Science Foundation of China (Grant No. 62202201).
Conflicts of interest
Jiang, Y. is an Editorial Board Member of the journal Complex Engineering Systems, but was not involved in any steps of the editorial process, notably including reviewer selection, manuscript handling, or decision making, while the other authors have declared that they have no conflicts of interest.
Ethical approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2026.
REFERENCES
1. Antinoro Pizzuto, E. A. Review of "The hands are the head of the mouth - The mouth as articulator in Sign Languages" by Penny Boyes Braem and Rachel Sutton-Spence (eds.). Sign Lang. Linguist. 2003, 6, 284-89.
2. Ong, S. C.; Ranganath, S. Automatic sign language analysis: a survey and the future beyond lexical meaning. IEEE. Trans. Pattern. Anal. Mach. Intell. 2005, 27, 873-91.
3. Tang, S.; He, J.; Guo, D.; Wei, Y.; Li, F.; Hong, R. Sign-IDD: iconicity disentangled diffusion for sign language production. In Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI-25). 2025, pp. 7266-74.
4. Bragg, D.; Koller, O.; Bellard, M.; et al. Sign language recognition, generation, and translation: an interdisciplinary perspective. In Proceedings of the 21st International ACM SIGACCESS Conference on Computers and Accessibility. New York, NY, USA; 2019, pp. 16-31.
5. Rastgoo, R.; Kiani, K.; Escalera, S. Sign language recognition: a deep survey. Expert. Syst. Appl. 2021, 164, 113794.
6. Sahoo, L. K.; Varadarajan, V. Deep learning for autonomous driving systems: technological innovations, strategic implementations, and business implications - a comprehensive review. Complex. Eng. Syst. 2025, 5, 2.
7. Wu, X.; Han, W.; Yang, H.; Han, H.; Qiao, J.; Peng, X. Robust multivariable tracking control for biological wastewater treatment process with external disturbances and uncertainties. Complex. Eng. Syst. 2025, 5, 12.
8. Freeman, W. T.; Roth, M. Orientation histograms for hand gesture recognition. In: International workshop on automatic face and gesture recognition. 1995, pp. 296-301. Available from: https://www.merl.com/publications/docs/TR94-03.pdf[Last accessed on 24 Apr 2026].
9. Sun, C.; Zhang, T.; Bao, B. K.; Xu, C.; Mei, T. Discriminative exemplar coding for sign language recognition with kinect. IEEE. Trans. Cybern. 2013, 43, 1418-28.
10. Hu, H.; Zhao, W.; Zhou, W.; Wang, Y.; Li, H. SignBERT: pre-training of hand-model-aware representation for sign language recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021, pp. 11087-96.
11. Gan, S.; Yin, Y.; Jiang, Z.; Xia, K.; Xie, L.; Lu, S. Contrastive learning for sign language recognition and translation. In Proceedings of the International Joint Conference on Artificial Intelligence; 2023, pp. 763-72.
12. Ren, Y.; Li, H.; Li, Y.; et al. Multi-modal isolated sign language recognition based on self-paced learning. Expert. Syst. Appl. 2025, 291, 128340.
13. Gao, L.; Zhu, L.; Hu, L.; Shi, P.; Wan, L.; Feng, W. A structure-based disentangled network with contrastive regularization for sign language recognition. Expert. Syst. Appl. 2025, 271, 126623.
14. Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 X 128 120db 30mw asynchronous vision sensor that responds to relative intensity change. In Proceedings of 2006 IEEE International Solid State Circuits Conference - Digest of Technical Papers. 2006, pp. 2060-69.
15. Brandli, C.; Berner, R.; Yang, M.; Liu, S. C.; Delbruck, T. A 240×180 130 db 3 μs latency global shutter spatiotemporal vision sensor. IEEE. J. Solid. State. Circuits. 2014, 49, 2333-41.
16. Mitrokhin, A.; Fermuller, C.; Parameshwara, C.; Aloimonos, Y. Event-based moving object detection and tracking. In Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2018, pp. 1-9.
17. Zhang, J.; Yang, X.; Fu, Y.; Wei, X.; Yin, B.; Dong, B. Object tracking by jointly exploiting frame and event domain. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV). 2021, pp. 13043-52.
18. Zhang, P., Yin, H., Wang, Z., et al. EvSign: sign language recognition and translation with streaming events. InProceedings of the Computer Vision - ECCV 2024: 18th European Conference; 2024, pp. 335-51.
19. Jiang, Y.; Wang, Y.; Li, S.; et al. EvCSLR: Event-guided continuous sign language recognition and benchmark. IEEE. Trans. Multimedia. 2025, 27, 1349-61.
20. Zhou, H.; Zhou, W.; Zhou, Y.; Li, H. Spatial-temporal multi-cue network for continuous sign language recognition. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20). 2020, pp. 13009-16.
21. Cui, R.; Liu, H.; Zhang, C. A deep neural framework for continuous sign language recognition by iterative training. IEEE. Trans. Multimedia. 2019, 21, 1880-91.
22. Liu, T.; Tao, T.; Zhao, Y.; Zhu, J. A two-stream sign language recognition network based on keyframe extraction method. Expert. Syst. Appl. 2024, 253, 124268.
23. De Castro, G. Z.; Guerra, R. R.; Guimarães, F. G. Automatic translation of sign language with multi-stream 3D CNN and generation of artificial depth maps. Expert. Syst. Appl. 2023, 215, 119394.
24. Lee, C.; Ng, K. K.; Chen, C.; Lau, H.; Chung, S.; Tsoi, T. American sign language recognition and training method with recurrent neural network. Expert. Syst. Appl. 2021, 167, 114403.
25. Guo, L.; Xue, W.; Guo, Q.; et al. Distilling cross-temporal contexts for continuous sign language recognition. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023, pp. 10771-80.
26. Hu, L.; Gao, L.; Liu, Z.; Feng, W. Continuous sign language recognition with correlation network. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023, pp. 2529-39.
27. Lu, H.; Salah, A. A.; Poppe, R. TCNet: continuous sign language recognition from trajectories and correlated regions. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence; 2024, pp. 3891-99.
28. Zheng, J.; Wang, Y.; Tan, C.; et al. CVT-SLR: contrastive visual-textual transformation for sign language recognition with variational alignment. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2023, pp. 23141-50.
29. Chen, Y.; Zuo, R.; Wei, F.; Wu, Y.; Liu S.; Mak, B. Two-stream network for sign language recognition and translation. arXiv 2022, 35, 17043-56.
30. Cihan Camgoz, N.; Koller, O.; Hadfield, S.; Bowden, R. Sign language transformers: joint end-to-end sign language recognition and translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020, pp. 10023-33.
31. Hao, A.; Min, Y.; Chen, X. Self-mutual distillation learning for continuous sign language recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021, pp. 11303-12.
32. Zuo, R.; Mak, B. C2SLR: consistency-enhanced continuous sign language recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022, pp. 5131-40.
33. Gao, W.; Fang, G.; Zhao, D.; Chen, Y. A Chinese sign language recognition system based on SOFM/SRN/HMM. Pattern. Recogn. 2004, 37, 2389-402.
34. Koller, O.; Zargaran, S.; Ney, H. Re-sign: re-aligned end-to-end sequence modelling with deep recurrent CNN-HMMs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017, pp. 4297-305.
35. Graves, A.; Fernandez, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning; 2006, pp. 369-76.
36. Koller, O.; Zargaran, S.; Ney, H.; Bowden, R. Deep sign: hybrid CNN-HMM for continuous sign language recognition. 2016, pp. 136.
37. Zhang, J.; Wang, Q.; Wang, Q. A sign language recognition framework based on cross-modal complementary information fusion. IEEE. Trans. Multimedia. 2024, 26, 8131-44.
38. Jiao, P.; Min, Y.; Li, Y.; Wang, X.; Lei, L.; Chen, X. CoSign: exploring co-occurrence signals in skeleton-based continuous sign language recognition. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV); 2023, pp. 20676-86.
39. Hu, L.; Gao, L.; Liu, Z.; Feng, W. Self-emphasizing network for continuous sign language recognition. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence. 2023, pp. 854-62.
40. Duarte, A.; Palaskar, S.; Ventura, L.; et al. How2Sign: a large-scale multimodal dataset for continuous American sign language. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021, pp. 2735-44.
41. Parelli, M.; Papadimitriou, K.; Potamianos, G.; Pavlakos, G.; Maragos, P. Spatio-temporal graph convolutional networks for continuous sign language recognition. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2022, pp. 8457-61.
42. Kumar, P.; Gauba, H.; Pratim Roy, P.; Prosad Dogra, D. A multimodal framework for sensor based sign language recognition. Neurocomputing 2017, 259, 21-38.
43. Oszust, M.; Krupski, J. Isolated sign language recognition with depth cameras. Procedia. Comp. Sci. 2021, 192, 2085-94.
44. Zheng, L.; Liang, B. Sign language recognition using depth images. In Proceedings of the 2016 14th International Conference on Control, Automation, Robotics and Vision (ICARCV); 2016, pp. 1-6.
45. Jiang, Y.; Wang, Y.; Li, S.; Zhang, Y.; Zhao, M.; Gao, Y. Event-based low-illumination image enhancement. IEEE. Trans. Multimedia. 2024, 26, 1920-31.
46. Gao, Y.; Li, S.; Li, Y.; Guo, Y.; Dai, Q. SuperFast: 200× video frame interpolation via event camera. IEEE. Trans. Pattern. Anal. Mach. Intell. 2023, 45, 7764-80.
47. Rebecq, H.; Ranftl, R.; Koltun, V.; Scaramuzza, D. High speed and high dynamic range video with an event camera. IEEE. Trans. Pattern. Anal. Mach. Intell. 2019, 43, 1964-80.
48. Liu, S.; Alexandru, R.; Dragotti, P. L. Convolutional ISTA network with temporal consistency constraints for video reconstruction from event cameras. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. 2022, pp. 1935-39.
49. Zhang, L.; Zhang, H.; Zhu, C.; Guo, S.; Chen, J.; Wang, L. Fine-grained video deblurring with event camera. In Proceedings of the 27th International Conference. Springer; 2021, pp. 352-64.
50. Chen, H.; Teng, M.; Shi, B.; Wang, Y.; Huang, T. A residual learning approach to deblur and generate high frame rate video with an event camera. IEEE. Trans. Multimedia. 2022, 25, 5826-39.
51. Li, J.; Li, J.; Zhu, L.; Xiang, X.; Huang, T.; Tian, Y. Asynchronous spatio-temporal memory network for continuous event-based object detection. IEEE. Trans. Image. Process. 2022, 31, 2975-87.
52. Shi, Q.; Ye, Z.; Wang, J.; Zhang, Y. QISampling: an effective sampling strategy for event-based sign language recognition. IEEE. Signal. Process. Lett. 2023, 30, 768-72.
53. Vasudevan, A.; Negri, P.; Di Ielsi, C.; Linares-Barranco, B.; Serrano-Gotarredona, T. SL-animals-DVS: event-driven sign language animals dataset. Pattern. Anal. Appl. 2022, 25, 505.
54. Vasudevan, A.; Negri, P.; Linares-Barranco, B.; Serrano-Gotarredona, T. Introduction and analysis of an event-based sign language dataset. In Proceedings of the 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020); 2020, pp. 675-82.
55. Wang, Y., Zhang, X., Wang, Y., Wang, H., Huang, C., Shen, Y. Event-based american sign language recognition using dynamic vision sensor. In Proceedings of the Wireless Algorithms, Systems, and Applications: 16th International Conference. 2021, Proceedings, Part Ⅲ 16. Springer; 2021, pp. 3-10.
56. Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast networks for video recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019, pp. 6201-10.
57. Camgoz, N. C.; Hadfield, S.; Koller, O.; Ney, H.; Bowden, R. Neural sign language translation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018, pp. 7784-93.
58. Hu, Y.; Liu, S.; Delbruck, T. v2e: from video frames to realistic DVS events. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2021, pp. 1312-21.
59. Min, Y.; Hao, A.; Chai, X.; Chen, X. Visual alignment constraint for continuous sign language recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021, pp. 11542-51.
60. Hu, L., Gao, L., Liu, Z., Feng, W. Temporal lift pooling for continuous sign language recognition. In: Lecture Notes in Computer Science. Cham: Springer; 2022. pp. 511-27.
61. Alyami, S.; Luqman, H. Swin-MSTP: swin transformer with multi-scale temporal perception for continuous sign language recognition. Neurocomputing 2025, 617, 129015.
62. Selvaraju, R. R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: visual explanations from deep networks via gradient-based localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV); 2017, pp. 618-26.
63. Gan, S.; Yin, Y.; Jiang, Z.; Wen, H.; Xie, L.; Lu, S. SignGraph: a sign sequence is worth graphs of nodes. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024, pp. 13470-79.
64. Zuo, R.; Wei, F.; Mak, B. Towards online continuous sign language recognition and translation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing; 2024, pp. 11050-67.
Cite This Article
How to Cite
Download Citation
Export Citation File:
Type of Import
Tips on Downloading Citation
Citation Manager File Format
Type of Import
Direct Import: When the Direct Import option is selected (the default state), a dialogue box will give you the option to Save or Open the downloaded citation data. Choosing Open will either launch your citation manager or give you a choice of applications with which to use the metadata. The Save option saves the file locally for later use.
Indirect Import: When the Indirect Import option is selected, the metadata is displayed and may be copied and pasted as needed.
About This Article
Copyright

Data & Comments
Data
0












Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at [email protected].