



fig1
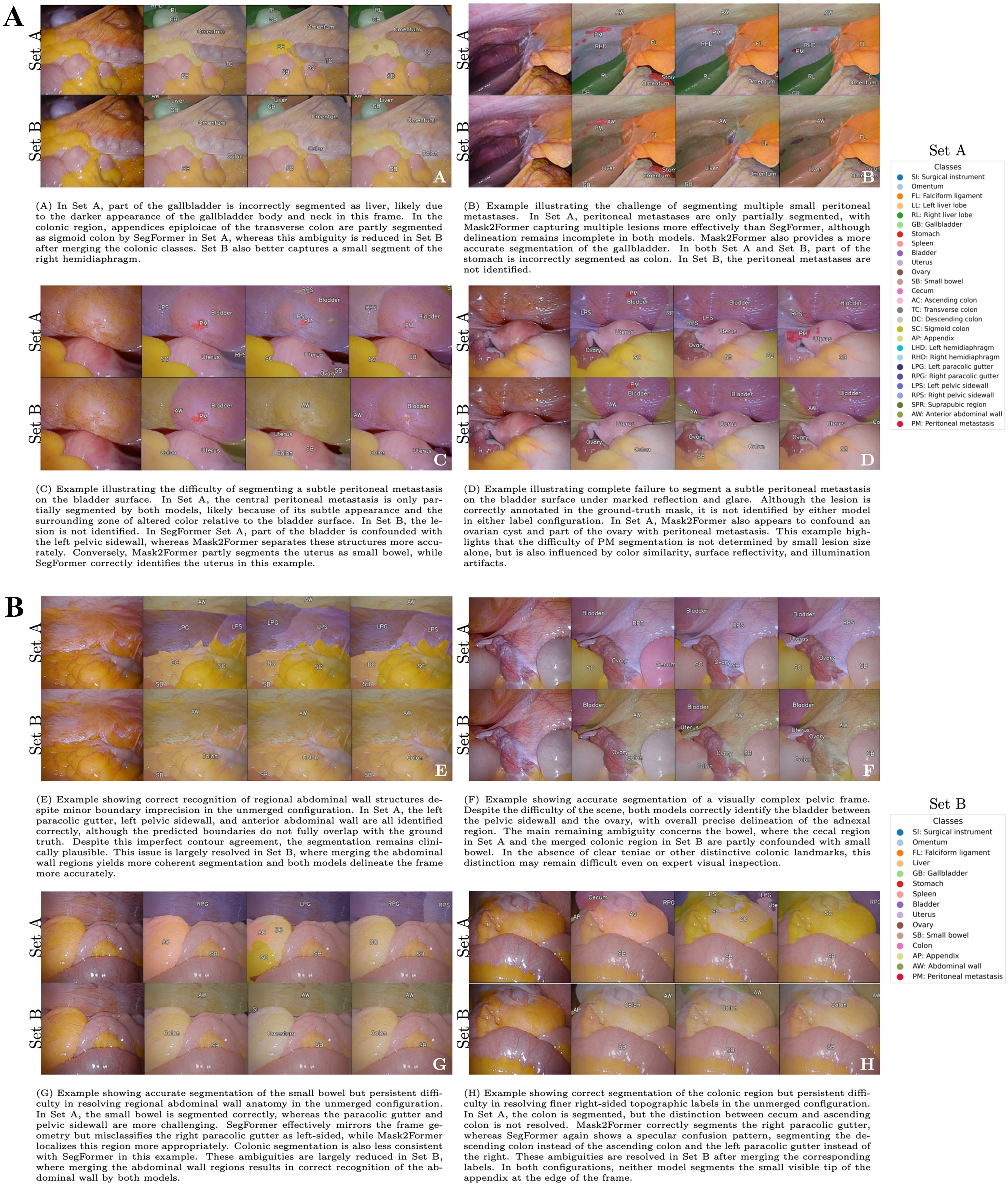
Figure 1. Semantic segmentation of intraoperative laparoscopic scenes. From left to right, each example shows the input frame, ground-truth annotation, SegFormer prediction, and Mask2Former prediction. The upper row corresponds to Set A and the lower row to Set B.




