

AI agents: opportunity, hype, and the way through
 0
0 
MAINTEXT
The current wave of artificial intelligence (AI) agents has arrived with remarkable speed. Some treat it as the inevitable next chapter after foundation models; others see it as another cycle of inflated promises. From the perspective of materials research, both reactions are understandable - and both miss the point. An agent is not “a model that chats better”. An agent is a work system that turns knowledge into outcomes[1]. That is why the topic attracts attention, why it invites hype, and why it will still matter after the hype has passed.
For materials research, the central question is surprisingly concrete[2]: can an agent connect the chain that actually determines research velocity and credibility -
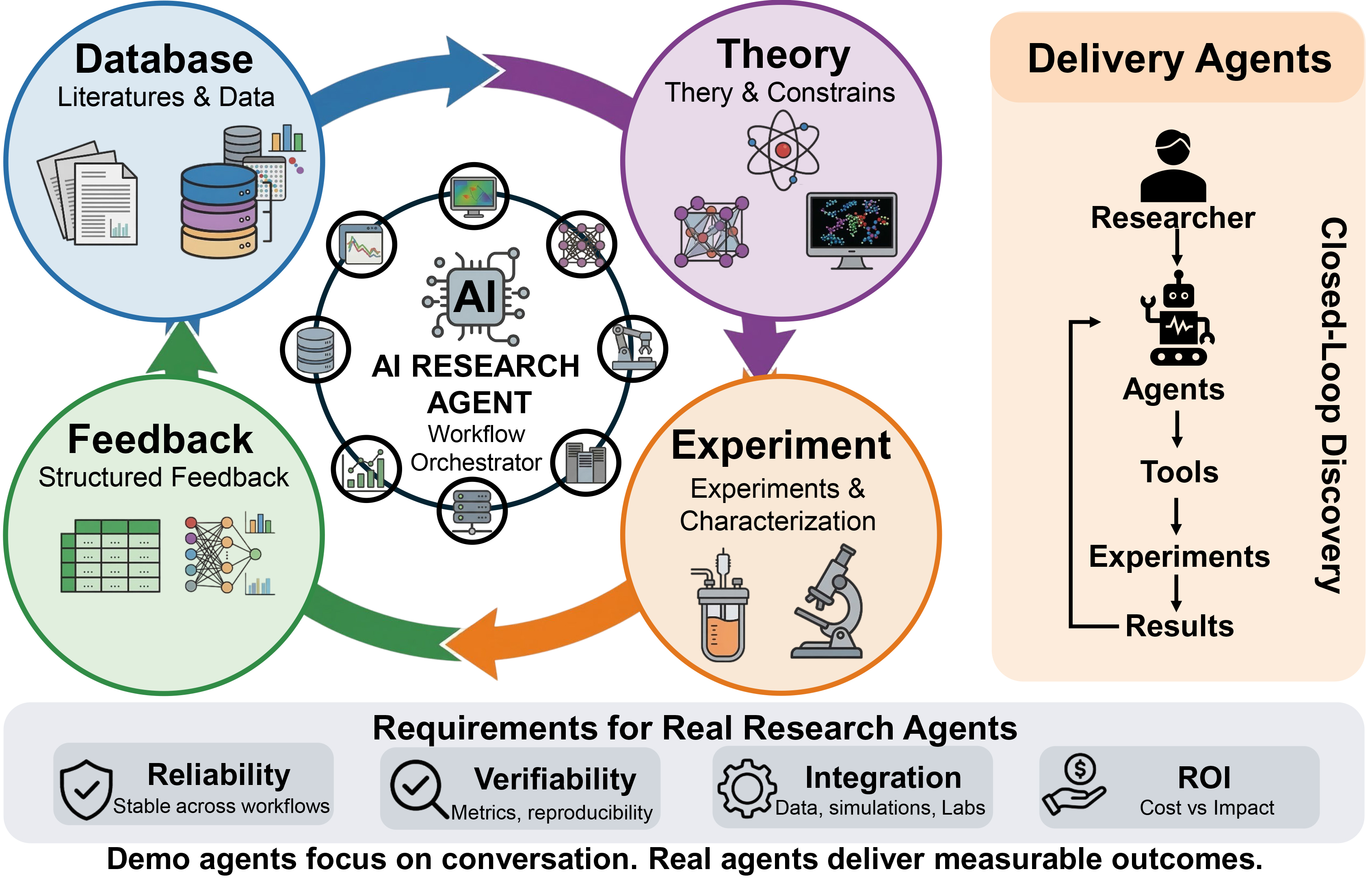
Figure 1. Framework of closed-loop discovery driven by AI Research Agents. Unlike conversational demo agents, real research agents act as workflow orchestrators at the center of the materials discovery cycle, seamlessly connecting literature databases, theoretical constraints, experimental characterization, and structured feedback. The right panel illustrates the paradigm shift toward “Delivery Agents”, where models delegate tasks to tools to execute physical experiments. Bottom panel outlines the four critical requirements - Reliability, Verifiability, Integration, and ROI - necessary for transitioning agents from conceptual demonstrations to deployable research infrastructure. AI: Artificial intelligence; ROI: return on investment.
FROM ANSWERING QUESTIONS TO MOVING PROJECTS
For years, AI for Science has often been framed around prediction: can a model infer properties, rank candidates, or forecast performance? Those are important problems, but they are not always the main bottleneck. In real materials projects, what slows us down is frequently the cost of execution rather than the lack of ideas. A single candidate material has to move through an extended sequence: finding and interpreting the relevant literature, collecting and cleaning data, setting constraints and assumptions, running computation, designing experiments, executing synthesis, measuring, characterizing, debugging failures, and then returning to theory for interpretation and next-step decisions. Each step is a potential choke point, and the friction accumulates.
Foundation models created a new interface: they can interpret scientific intent expressed in natural language. That matters because scientists do not think in application programming interface (API) calls; we think in goals, constraints, and trade-offs. However, language capability alone does not advance projects. What changes the research tempo is the ability to act - to call tools, orchestrate workflows, handle exceptions, and produce deliverables that stand up to scrutiny. That is where agents enter the story. The promise of an agent is not that it “knows more”, but that it can help research progress.
This is also why the current moment is a genuine window for agents. Many parts of research operations are repetitive and structured: initial screening, dataset preparation, job queue submission, report drafting, results formatting, archiving, and routine analysis. Historically, these steps were handled through time-consuming manual labor. Meanwhile, the tool ecosystem is becoming more callable: databases, simulation pipelines, lab information systems, and automation platforms increasingly offer interfaces that can be orchestrated. Finally, as materials research becomes more connected to industrial translation, the demand for traceability and auditability grows stronger. A system that can record what it did, what evidence it used, and why it made a decision is fundamentally more trustworthy than a system that simply generates persuasive text.
WHERE THE REAL OPPORTUNITY SITS
It is tempting to reduce the agent conversation to writing: literature reviews, proposals, and reports. Those are obvious near-term wins, but they are not the core. The deeper shift is a change in research interaction - from Question and Answer (Q&A) to delegation. A Q&A system gives you an answer. A delegation system produces a deliverable that is ready to be tested, evaluated, and revised.
In materials research, “deliverable” has a specific meaning. It does not refer to a confident paragraph; it refers to an actionable plan grounded in evidence and bounded by constraints. This is why an agent’s usefulness is best judged by whether it can perform four kinds of work[1], corresponding to the four core nodes of the closed-loop discovery cycle in Figure 1.
First, it should convert scattered information into structured evidence. The research world is not short on papers. It is short on usable knowledge. A serious agent must be able to extract key variables - composition, synthesis conditions, characterization protocols, measurement environments, uncertainty ranges, and negative results - into formats that can be screened, compared, and reused. Otherwise, it is simply producing narrative summaries.
Second, it should translate theory into executable constraints. Materials are not discovered by optimism. Thermodynamic stability, phase equilibria, electrochemical stability windows, reaction pathways, and interfacial effects impose hard boundaries. If these remain in prose, they cannot scale. When they become rules and workflows, they compress the search space from “anything” to “what is physically plausible and experimentally feasible”.
Third, it should shift experiments from trial-and-error to design. A strong agent does not merely recommend a material. It proposes an experimental design: which variables matter most, what ranges to scan, what controls to include, what measurements are essential for diagnosis, and what failure modes to anticipate. The most expensive research is not research that fails - it is research that fails without learning.
Fourth, and most importantly, it must enable feedback. In real discovery, results do not conclude the story; they start the next cycle. If experimental outcomes - positive or negative - are not written back in structured form, the system does not improve. Without feedback, an agent remains a one-off assistant. With feedback, it begins to behave as a system that improves as it operates.
WHY THE HYPE IS SO EASY TO GENERATE
If that is the real target, it becomes clear why hype is common. Many “agents” today have an impressive voice but no legs. They can describe what to do, but they do not actually do it in a way that survives real-world constraints.
One common pattern is rebranding multi-turn dialogue as an agent. Long context and well-crafted prompts can produce convincing step-by-step plans, but that does not constitute execution. Another pattern is confusing a beautiful demo with a deployable system. Demos succeed because the environment is controlled: the data format is known, the permissions are granted, the edge cases are avoided, and failures are not stress-tested. Real research is the opposite: formats change, tools break, dependencies drift, and exceptions are the default rather than the anomaly. A third pattern is treating model capability as research capability. Models can be strong at language and reasoning, yet fail at what matters in production: stability, cost discipline, safety, compliance, and traceability.
Hype is not entirely harmful. It accelerates attention and funding, which can be useful. The danger is that it convinces people the hard problems are already solved. In materials research, they are not.
THE FOUR GATES AN AGENT MUST PASS
To function as real research infrastructure, an agent must pass four gates, which constitute the baseline requirements for real research agents [Figure 1, bottom panel].
The first gate is reliability over time. A single successful run proves almost nothing. The system must remain stable across different materials families, shifting data distributions, different labs, and different users. Research is particularly unforgiving because “correct by coincidence” is worse than obviously wrong - it wastes weeks.
The second gate is verifiability. If a system cannot be evaluated against objective acceptance criteria, it will drift toward persuasive storytelling. Agents need measurable outcomes: reproducibility rates, hit rates, time saved, failure-rate reduction, and performance against baselines. In short, they need a way to be held accountable.
The third gate is real integration with tools and data. Text-only agents inevitably collapse into content generation. Research value is created when agents can retrieve from curated databases, run scripts, submit compute jobs, parse outputs, and write results back. Integration is not a technical detail; it is the difference between a writing assistant and a research system.
The fourth gate is return on investment (ROI). Inference cost, tool-calling cost, human fallback cost, and the cost of failure all matter. If you cannot balance the books, you cannot scale.
HOW TO TELL A REAL AGENT FROM A DEMO
In practice, you do not need to hear about architecture to judge an agent. You can simply ask three questions.
Can it close the loop? What is the input, what tools are called, what is delivered, and how do results flow back? If feedback is missing, it is not a loop, and it will not scale.
Can it be accepted and measured? Are there metrics, baselines, and reproducible evaluation protocols? If not, it is a content tool, not a delivery system.
Does it have safeguards and traceability? Does it stop when uncertain, require human confirmation at critical steps, log every action, and provide traceable evidence? Without these, risk accumulates quickly in research contexts.
If a project cannot answer these three questions, it is almost certainly optimized for demonstration rather than deployment. As summarized at the bottom of Figure 1, demo agents focus on conversation, whereas real “delivery agents” drive a continuous pipeline from researchers to tools, experiments, and actionable results to deliver measurable outcomes.
A PRACTICAL PATH THROUGH THE NOISE
So how do you build something real in a noisy environment? The best approach is to move from “agent narratives” back to task-system engineering. Build a system that delivers on a narrow task, make it reliable, and then let it grow into an agent.
The most robust route is a three-step path.
Start with a high-frequency, hard-need, measurable task. Avoid the temptation of a “general research assistant”. Choose workflows that are repetitive, costly, and evaluable: data extraction and cleaning, initial candidate screening, parameter-space suggestion, automated queue management, and structured write-back of lab records. A module that reliably saves 30% of human effort is more valuable than a broad assistant that fails unpredictably.
Contain non-deterministic models with deterministic tools. Let the model handle intent understanding, decomposition, and natural-language interface. Let deterministic tools handle retrieval, computation, constraints, and boundary checks. In one line: let the model command, but let tools execute. This is also the most effective way to suppress hallucinations.
Finally, build controllable semi-automation before pushing for autonomy. Research resembles autonomous driving: start with human confirmations at critical nodes, ensure failures stop safely, keep logs traceable, and then gradually automate low-risk stages. Many teams fail by aiming for full autonomy on day one and collapsing reliability and safety in the process.
CLOSING: WHAT REMAINS AFTER THE WAVE
Every technology wave goes through expansion, correction, and consolidation. Agents will too. What remains will not be the loudest storytelling. It will be systems that are stable, measurable, traceable, and integrated.
In materials research, agents are likely to become infrastructure. However, the lasting form is unlikely to be a single universal chat interface. The form that survives is the chain that truly runs: database → theory → experiment → feedback. Whoever makes that chain work will turn “talking” into “doing”, and turn demonstrations into discovery.
CONCLUSION
Hype will fade, but agents that close the loop will remain. In materials research, the winners will not be those with the loudest narratives or the most theatrical demonstrations, but those who build systems that are stable, measurable, traceable, and integrated with real data and tools. The long-term outcome is unlikely to be a single “universal chat box”. Instead, AI agents will gradually settle into research infrastructure - modular systems that reliably connect database, theory, experiment, and feedback. When that chain truly runs, “talking” becomes “doing”, and demonstrations become discovery.
DECLARATIONS
Authors’ contributions
Contributed to the writing and preparation of the manuscript: Zhao, C.; Li, H.
Availability of data and materials
Not applicable.
AI and AI-assisted tools statement
Not applicable.
Financial support and sponsorship
The authors thank the UW-TU Strategic Partner Funds.
Conflicts of interest
Zhao, C. is an Editorial Board member of AI Agent, and Li, H. is the Editor-in-Chief of AI Agent. None of these individuals were involved in any steps of the editorial process for this manuscript, including reviewer selection, manuscript handling, or decision-making. The other authors declared that there are no conflicts of interest.
Ethical approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2026.
REFERENCES
1. Zhang, D.; Jia, X.; Wang, Y.; et al. Digital materials ecosystem: from databases to AI agents for autonomous discovery. Chem. Sci. 2026, 17, 5782-804.
Cite This Article
How to Cite
Download Citation
Export Citation File:
Type of Import
Tips on Downloading Citation
Citation Manager File Format
Type of Import
Direct Import: When the Direct Import option is selected (the default state), a dialogue box will give you the option to Save or Open the downloaded citation data. Choosing Open will either launch your citation manager or give you a choice of applications with which to use the metadata. The Save option saves the file locally for later use.
Indirect Import: When the Indirect Import option is selected, the metadata is displayed and may be copied and pasted as needed.
About This Article
Copyright

Data & Comments
Data
0









Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at [email protected].